Data Validation Techniques and Procedures
Learn about various data validation methods including leave-p-out cross-validation, K-fold cross-validation, bootstrapping, and random forest. Understand how these techniques help analyze and validate predictive models for improved data accuracy and reliability.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
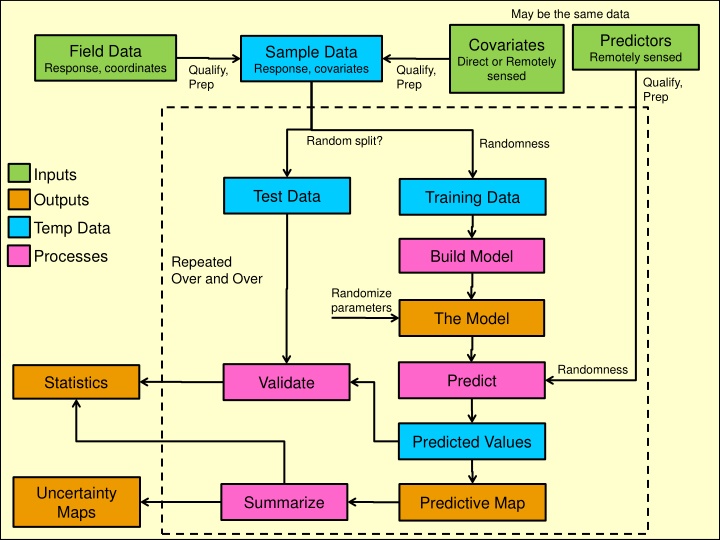
May be the same data Predictors Remotely sensed Covariates Direct or Remotely sensed Field Data Response, coordinates Sample Data Response, covariates Qualify, Prep Qualify, Prep Qualify, Prep Random split? Randomness Inputs Outputs Test Data Training Data Temp Data Processes Build Model Repeated Over and Over Randomize parameters The Model Randomness Predict Statistics Validate Predicted Values namNm15 Uncertainty Maps Summarize Predictive Map
May be the same data Predictors Remotely sensed Jackknife Covariates Direct or Remotely sensed Field Data Response, coordinates Sample Data Response, covariates Qualify, Prep Qualify, Prep Qualify, Prep Random split? Randomness Noise Injection Cross-Validation Inputs Outputs Test Data Training Data Temp Data Processes Build Model Repeated Over and Over Monte-Carlo Randomize parameters The Model Sensitivity Testing Randomness Predict Statistics Validate Noise Injection Predicted Values namNm15 Uncertainty Maps Summarize Predictive Map
Cross-Validation Split the data into training (build model) and test (validate) data sets Leave-p-out cross-validation Validate on p samples, train on remainder Repeated for all combinations of p Non-exhaustive cross-validation Leave-p-out cross-validation but only on a subset of possible combinations Randomly splitting into 30% test and 70% training is common namNm15
K-fold Cross Validation Break the data into K sections Test on ??, Training remainder Repeat for all ?? 10-fold is common Test 1 2 3 4 5 6 Training 7 8 namNm15 9 10
Bootstrapping Drawing N samples from the sample data (with replacement) Building the model Extract and record performance stats Repeating the process over and over Create summary stats namNm15
Random Forest N samples drawn from the data with replacement Repeated to create many trees A random forest Splits are selected based on the most common splits in all the trees Bootstrap aggregation or Bagging namNm15
Boosting Can a set of weak learners create a single strong learner? (Wikipedia) Lots of simple trees used to create a really complex tree "convex potential boosters cannot withstand random classification noise, 2008 Phillip Long (at Google) and Rocco A. Servedio (Columbia University) namNm15
Boosted Regression Trees BRTs combine thousands of trees to reduce deviance from the data Currently popular More on this later namNm15
Sensitivity Testing Injecting small amounts of noise into our data to see the effect on the model parameters. Plant The same approach can be used to model the impact of uncertainty on our model outputs and to make uncertainty maps Note: I call this noise injection to separate it from sensitivity testing for model parameters namNm15
Jackknifing Trying all combinations of covariates Given covariates 1,2,3 Try: 1 2 3 1,2 1,3 2,3 1,2, 3 namNm15
Jackknife Field Data Response, coordinates Covariates Direct or Remotely sensed Qualify, Prep Qualify, Prep Sample Data Response, covariates Cross-Validation Noise Injection Inputs Outputs Test Data Training Data Temp Data Processes Build Model Repeated Over and Over Monte-Carlo Randomize parameters The Model Sensitivity Testing Predict Statistics Validate Noise Injection Predicted Values namNm15 Uncertainty Maps Summarize Predictive Map
May be the same data Predictors Remotely sensed Jackknife Covariates Direct or Remotely sensed Field Data Response, coordinates Sample Data Response, covariates Qualify, Prep Qualify, Prep Qualify, Prep Random split? Randomness Noise Injection Cross-Validation Inputs Outputs Test Data Training Data Temp Data Processes Build Model Repeated Over and Over Monte-Carlo Randomize parameters The Model Sensitivity Testing Randomness Predict Statistics Validate Noise Injection Predicted Values namNm15 Uncertainty Maps Summarize Predictive Map
Response Data Drives Method Binary (true/false): GLM w/Logistic Linear: Linear regression Categorical: CART w/Classification Logarithmic or exponential: Non-uniform residuals: General LM? Homoscedastic: GAM Other continuous: GAM More to come! namNm15
Linear GLM GAM CART Maxent HEMI 2 Number of predictors N N N N N 10 Max Linear (or linearized) Logit, etc. Link + splines (typical) Trees Linear, product, threshold, etc. Search for best solution Bezier Curves Base equation Fitting approach Direct analytic solution Direct analytic solution Solve derivative for maximum likelihood Continuous Direct analytic solution? Search for best solution Response variable Continuous Continuous or Binomial Continuous or categorical Presence- only Presence- only Covariates Continuous Continuous Continuous or categorical Continuous or categorical Continuous or categorical Continuous or categorical Uniform residuals Independen t samples Complexity Yes No Yes Maybe? Yes Yes Yes Yes Yes Yes Yes Yes namNm15 Simple Simple Moderate Varies Complex Moderate Over fit No No Unlikely Varies Likely w/defaults Unlikely
Model Optimization & Selection Modeling method Independent variable selection Covariates/predictor variables Coefficient estimation (fitting) Validation: Against sub-sample of data Against new dataset Parameter sensitivity Uncertainty estimation namNm15




































