Learn about the innovative approaches, including rule-based and LLM-based systems, for de-identifying sensitive information in PDFs presented by Pierre Lison and the team at the Norwegian Health Archive. Explore how these methods help protect patient privacy during the CLEANUP seminar on November 7, 2023.
Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
De-identification of PDFs with multimodal transformers Pierre Lison + the team at the Norwegian Health Archive (with help from Ildik Pil n and Jeremy Barnes) CLEANUP seminar, November 7 2023
Objective Categories 1. Patient name 2. Date of birth 3. Personal number 4. Phone number 5. Home address 6. Next of kin Bounding boxes where personal identifiers are found Patient record from the Norwegian Health Archives (long scanned PDF)
First prototype (rule-based) 1. Extract the image and text on each page (and post process it, including to correct some common OCR errors) 2. Find personal identifiers through predefined text patterns, for instance: F dselsnr.: [sequence of 11 digits]") 1. Search for occurrences of these entities through the rest of the document
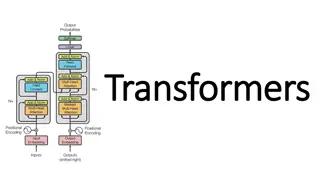
Second prototype (LLM-based) LayoutXLM: combination of a large language model and a neural image recognition model The embeddings for each token combine: The token embeddings from the LLM The visual embeddings for the token using a CNN encoder Position embeddings, both text-based and layout-based To run the model on a page, we need to provide a text (sequence of words), an image, and the bounding boxes of each word
Second prototype (LLM-based) LayoutXLM model fine-tuned on sequence- labelling task Problem: on which training data? Current solution: use the entities found with rule- based system Seems to give good results Although errors of rule-based system are reproduced by the LLM Still need to do thorough evaluation





")
")
")