LSTM Core Concepts
The long short-term memory (LSTM) model is a crucial component in understanding recurrent neural networks. It comprises key ideas such as backbone state carrying and gradient modulation through gating mechanisms. The core concepts involve forget gates, input gates, updates to the internal state, and output gates, each contributing to the model's efficacy in information processing and retention. Additionally, the Gated Recurrent Unit (GRU) is presented as an alternative unit for combining and managing states in neural networks. Furthermore, the role of dropout in regularizing weights to prevent overfitting in RNNs is discussed. Various images and explanations further elucidate these intricate processes.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
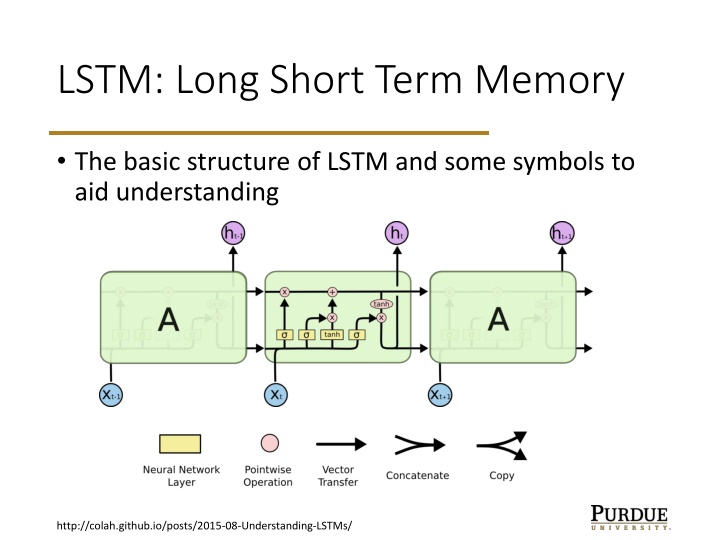
LSTM: Long Short Term Memory The basic structure of LSTM and some symbols to aid understanding http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM core ideas Two key ideas of LSTM: A backbone to carry state forward and gradients backward. Gating (pointwise multiplication) to modulate information flow. Sigmoid makes 0 < gate < 1. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM gating: forget The fgate is forgetting. Use previous state, C, previous output, h, and current input, x, to determine how much to suppress previous state. E.g., C might encode the fact that we have a subject and need a verb. Forget that when verb found. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM gating: input gate Input gate i determines which values of C to update. Separate tanh layer produces new state to add to C. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM gating: update to C Forget gate does pointwise modulation of C. Input gate modulates the tanh layer this is added to C. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM gating: output o is the output gate: modulates what part of the state C gets passed (via tanh) to current output h. E.g., could encode whether a noun is singular or plural to prepare for a verb. But the real features are learned, not engineered. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
GRU: Gated Recurrent Unit Combine C and h into a single state/output. Combine forget and input gates into update gate, z. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
RNN dropout Dropout is used to regularize weights and prevent co- adaptation. Dropout for RNNs must respect the time invariance of weights and outputs. In Keras GRU, dropout applies vertically, recurrent_dropout applied horizontally. https://arxiv.org/pdf/1512.05287.pdf