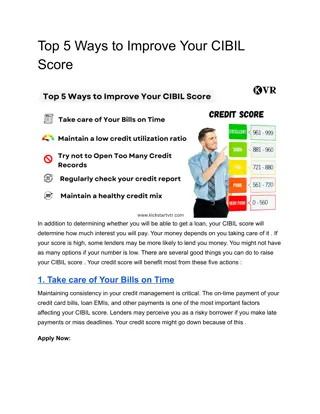
Understanding Propensity Score Matching in Causal Inference
Explore the concept of propensity score matching for estimating treatment effects in non-randomized studies. Learn about the challenges of bias and model dependence, and how matching can address these issues effectively.

Uploaded on | 2 Views
Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
D'Amore-McKim School of Business - Northeastern University Propensity Score Matching Propensity Score Matching A Primer in A Primer in R R David Zepeda Assistant Professor Supply Chain & Information Management d.zepeda@neu.edu Center for Health Policy and Healthcare Research Brown Bag Series April 1, 2015 1
Outline 1. Problem description 2. Theory 3. Two-Step Approach 4. Implementation in R 5. Example 1 Hospitals 6. Example 2 Primary Care Clinics 7. Example 3 Farm Land 8. References 2
Problem Consider a study with n observational units. There are two treatment states, 0 and 1. The response of the ith unit is indicated by ?1? if the ith unit received treatment = 1 and ?0? if the ith unit received treatment = 0. Mean causal effect = ?(?1?) ?(?0?) 3
Problem The goal is to estimate the average effect over observations. Let ?? be a vector of the characteristics of the unit (i.e., covariates) that are not consequences of the treatment. The mean causal effect averaged over all units is the average treatment effect (ATE). ATE = 1 ? ? ?=1 ?(?1?|??) ?(?0?|??) 4
Problem An observational unit is generally assigned only one of the two treatments. The treatment is not randomly assigned. Results in a number of potential problems regarding bias and model dependence. 5
Problem Source: Ho, D. E., Imai, K., King, G. & Stuart, E.A. 2007. Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference. Political Analysis, 15:199-236. 6
Theory Let T be an indicator of treatment ??= 0, treatment = 0 treatment = 1 1, Now compare a randomly selected treated unit to a randomly selected control unit. Because conditioning on T, the difference between two randomly selected observational units is not in general the mean causal effect! ? ?1???= 1 ? ?0???= 0 ?(?1?) ?(?0?) 7
Theory But, if treatment assignment is (?0,?1) ?|?, then we have ? ?1???= 1 ? ?0???= 0 = ??? ?1???= 1,?? ? ?0???= 0,?? = ??? ?1??? ? ?0??? = ?(?1?) ?(?0?) 8
Theory A tool used to estimate treatment effects is a balancing score . Suppose ? ? is a function of covariates ? such that ? ? ? ? ,? = 1 = ? ? ? ? ,? = 0such that? ?|? ? Sampling a treated and control unit with the same value of ? ?we have ? ?1? ? ,? = 1 ? ?0? ? ,? = 0 = ??(?)? ?1? ? ,? = 1 ? ?0? ? ,? = 0 = ??(?)? ?1? ? = ?(?1) ?(?0) ? ?0? ? 9
Theory A propensity score is p ? = Pr ? = 1 ? = ? ? ? . The true propensity score is a balancing score such that if treatment and control groups have identical propensity score distributions then all covariates are balanced between the two groups. Therefore, we can use logistic regression or another approach (i.e., probit) to estimate p ? so we can get matched samples! Can now use same parametric analysis on the matched dataset as would have been used to analyze the original raw dataset prior to propensity score matching. 10
Two-Step Approach 1. Preprocessing via matching Distributions of ? be matched as closely as possible (i.e., balance) Relationship between T and ? is eliminated Do not introduce bias Do no increase inefficiency too much Create a dataset closer to an experiment 2. Parametric analysis after matching Holding covariates constant Increase robustness Less sensitive to modeling assumptions A variety of treatment effects can be analyzed (i.e., ATE) 11
Implementation in R What is R? A language and environment for statistical computing and graphics Provides a wide variety of statistical and graphical techniques Is highly extensible Provides an Open Source route to participation Great care has been taken over the defaults for the minor design choices in graphics User retains full control Available as Free Software! Allows users to add additional functionality Can be extended (easily) via packages. The R Project for Statistical Computing http://www.r-project.org/ 12
Implementation in R MATCHITPackage Dichotomous treatment variable Experimental and observational data Improving parametric statistical models Reduces model dependence Semi-parametric and non-parametric preprocessing Assess covariate distributions in the two groups (i.e., balance) Large range of matching methods Exact Subclassification Nearest neighbor Optimal Genetic 13
Implementation in R Exact matching Simplest version of matching Match each treated unit to all possible control units Exactly the same values on all the covariates Sufficient matches often cannot be found Subclassification Forms subclasses with close distributions of covariates Various subclassification schemes Can be used in conjunction with other matching methods Nearest neighbor matching Selects best control matches for each treated unit Chooses the control unit not yet matched closest to treated unit 14
Implementation in R Optimal matching Finds matched samples with smallest average absolute distance Helpful when there are not many appropriate control matches Genetic matching Uses a genetic search algorithm Optimal balance achieved after matching Performs statistical tests for determining balance Variety of options for matching methods Number of matched control units Matching with or without replacement Kernel matching Discard treated units, control units, or both Number of subclasses Distance measurement (i.e., logit) 15
Example 1 Association between hospital system affiliation and hospital inventory in California hospitals (Zepeda, Nyaga, & Young, WP 2015) California hospital data from 2007 2009 878 observations (126 affiliated with smaller hospital systems) Preprocessing of data on affiliation with smaller hospital systems Genetic matching method 2 control observations with replacement for every treated observation 126 observations in treatment group 156 observations in control group Propensity score balancing improved by 95% 16
Example 1 17
Example 2 Association between IT-leveraging capability and high quality diabetes care in Minnesota primary care clinics (Zepeda & Sinha, WP 2015) Minnesota primary care clinics in 2010 450 observations (135 with high IT-leveraging capability) Preprocessing of data on high IT-leveraging capability Optimal matching method 1 control observations without replacement for every treated observation 135 observations in treatment group 135 observations in control group Propensity score balancing improved by 76% 18
Example 2 19
Example 3 Effect of easements on the selling price of farms in Minnesota (Taff & Weisberg, 2007) Federal Conservation Reserve Program (CRP) Temporary conservation easement by USDA (10-15 years) Annual payment by USDA for enrolled land Land valuation theory predicts that temporary easements should have no effect on value of properties Data Oct 1, 2002 Sep 30, 2004 Farm properties with short-term conservation easements Farm properties with no conservation easements Covariates 2,937 property sales (271 were restricted by CRP contracts) 20
Example 3 The primary objective Compare 271 sales with CRP restrictions to sales without Standard observational study approach Use all sales with no CRP as a comparison group Potential problem Properties sold without a random assignment Differences between observable sample and target population may be a cause for bias Using propensity score matching Mimic a randomized experiment Sample of non-CRP and CRP sales Closely agree on salient property characteristics (i.e., balance) 21
Example 3 Medians Upper 75% Lower 25% Dotted lines = 95% 22
Example 3 Six models developed and tested Models 1 3: use all data, CRP and portion of land RESTRICTED Model 4: restricts data to sales with PRODUCTIVITY measure Model 5: matched sample on CRP restriction Model 6: matched sample with PRODUCTIVITY measure Consistency in results CRP contracts negatively associated with sales prices Most of CRP effect is captured by RESTRICTED amount Counter to land valuation theory 23
Example 3 24
References The R Project for Statistical Computing http://www.r-project.org/ MATCHITR Package http://gking.harvard.edu/matchit Ho, D. E., Imai, K., King, G. & Stuart, E.A. 2007. Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference. Political Analysis, 15:199-236. Examples Zepeda, D., Nyaga, G., & Young, G. 2015. Supply Chain Risk Management and Hospital Inventory: Effects of System Affiliation. Working Paper. Zepeda, D. & Sinha, K. IT-Leveraging Capability for Reducing Health Care Disparities: An Empirical Analysis of Primary Care Operations. Working Paper. Taff, S.J. & Weisberg, S. 2007. Compensated short-term conservation restrictions may reduce sales prices. The Appraisal Journal, Winter. 25
D'Amore-McKim School of Business - Northeastern University Thank You! Thank You! David Zepeda Assistant Professor Supply Chain & Information Management d.zepeda@neu.edu 26