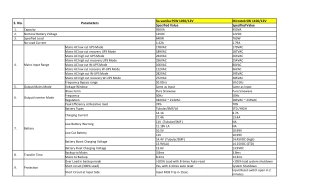
Understanding Transformer Architecture for Students
Explore the workings of the Transformer model, including Encoder, Decoder, Multi-Head Attention, and more. Dive into examples and visual representations to grasp key concepts easily. Perfect for students eager to learn about advanced neural network structures.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Transformer Transformer overview Encoder Decoder
How does the transformer work? EE I am a student encoder decoder
Decoder Encoder I am a Student. Decoder Encode r Decoder Encoder
Encoder Encoder Feed Forward Multi-Head Attention
Multi-head attention Z1 Zh Z2 ... X
Scaled Dot-Product Attention Z MatMul Z SoftMax Scaled Dot-Product Attention Scale K Q V Linear Linear Linear MatMul V K Q X
Example 0 1 0 1 0 1 1 1 1 0 0 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 1 1 2 3 0 1 0 0 3 0 X1: 1 X2: 0 0 1 0 1 0 2 1 1 0 1 0 2 1 WQ= WV= 2 X = 0 WK= 0 2 1 X : 1 1 1 1 3 Z 0 1 0 1 0 1 1 1 1 0 0 0 0 4 2 1 4 3 1 0 1 1 0 2 1 1 0 1 0 2 1 = K = XWK= 0 1 Scaled Dot-Product Attention 1 1 0 0 0 0 0 1 1 0 1 1 1 0 1 0 2 1 1 0 1 0 2 1 1 2 2 0 2 1 2 2 3 Q = XWQ= = K Q V Linear Linear Linear 0 0 1 1 2 3 0 1 0 0 3 0 1 0 1 0 2 1 1 0 1 0 2 1 1 2 2 2 8 6 3 0 3 V = XWV= = X
Scaling and SoftMax Z 1 2 2 0 2 1 2 2 3 0 1 1 4 4 0 2 3 = 4 1 2 4 4 MatMul QK?= 16 12 12 10 4 SoftMax 2 4 4 4 4 1.15 2.30 2.30 2.30 9.23 6.92 2.30 6.92 5.77 QK? 12 / 10 = 3 = 16 12 ?? Scale 0.14 0.43 0.90 0.75 0.43 0.09 0.24 QK? = 0.01 0.01 softmax ?? MatMul 1.86 2.00 1.99 6.32 7.81 7.48 1.71 0.27 0.74 QK? V Q K Z = softmax V = ??
Multi-head Attention Linear concat h
Encoder Feed Forward Multi-Head Attention
Feed Forward Linear 4XLinear
Encoder architecture Encoder Linear Feed Forward 4XLinear Multi-Head Attention howsam.org |
Encoder Norm & Residual connections Norm & Residual connections Norm Feed Forward Norm ( ) + Multi-Head Attention
Several layers of Encoders Several layers of Encoders r Encode . .. N r Encode r Encode
Whole in one image Whole in one image r Encode . .. N r Encode r Encode
Decoder Decoder Add & Normalize Feed Forward Add & Normalize Multi-Head Attention Q K,V Add & Normalize Masked Multi-Head Attention
Decoder Add & Normalize Feed Forward Add & Normalize Multi-Head Attention Q K,V Add & Normalize Masked Multi-Head Attention
#N Decoder N . .. #1 Decoder
Friend My Hello ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? <sos> Hello My Hello my friend howsam.org |
Hello my friend Linear Decoder Encoder <sos> Hello my
frien hello my d K? Q hello my friend + = Decoder QK?+ Mask Z = softmax V ?? 0 0 0 0 Mask = 0 0
X1: 1 0 0 1 0 1 0 1 1 1 1 0 0 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 1 1 2 3 0 1 0 0 3 0 1 0 1 0 2 1 1 0 1 0 2 1 X2: 0 2 X = 0 WK= 0 2 WQ= WV= 1 X : 1 1 1 1 3 Z 0 1 0 1 0 1 1 1 1 0 0 0 0 4 2 1 4 3 1 0 1 1 0 2 1 1 0 1 0 2 1 = K = XWK= 0 1 Scaled Dot-Product Attention 1 1 0 0 0 0 0 1 1 0 1 1 1 0 1 0 2 1 1 0 1 0 2 1 1 2 2 0 2 1 2 2 3 Q = XWQ= = K Q V Linear Linear Linear 0 0 1 1 2 3 0 1 0 0 3 0 1 0 1 0 2 1 1 0 1 0 2 1 1 2 2 2 8 6 3 0 3 V = XWV= = X
Z 1 2 2 0 2 1 2 2 3 0 1 1 4 4 0 2 3 = 4 1 2 4 4 MatMul QK?= 16 12 12 10 4 SoftMax 2 4 4 1.15 2.30 9.23 6.92 2.30 6.92 5.77 QK? = 4 12 / 3 = 2.30 10 16 12 ?? 4 2.30 Mask 0 0 0 0 0 0 1.15 2.30 2.30 2.30 9.23 6.92 2.30 6.92 5.77 1.15 2.30 2.30 6.92 5.77 9.23 QK? + Mask = + = Scale ?? 1.00 0.00 0.00 0.00 0.99 0.75 0.00 0.00 0.24 QK? MatMul softmax = ?? K Q V 1.00 2 7.9 0 2.00 3.00 QK? Z = softmax V = 1.99 7.48 0.74 ?
Friend My Hello ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? <sos> Hello My Hello my friend howsam.org |
Hello my friend Linear Decoder Encoder <sos> Hello my
Positional Encoding Hello my friend Linear Decoder Encoder + + + + + + <sos> Hello my
1 ? = 2? ? = 2? + 1 sin ??? cos ??? ??= { ??,i= 2? 10000? i t
ViT Mlp Head Class ? MLP Transformer Encoder Norm 0* 1 2 3 4 5 6 7 8 9 Patch + Position Embedding Multi-Head Attention Linear Projection of Flatten Patches Norm Embedded Patches