Acoustic Modeling and Hidden Markov Model in Speech Processing

This content presents a detailed overview of acoustic modeling, featuring concepts like feature extraction, Gaussian mixture models, and solving basic problems in speech processing. It also delves into Hidden Markov Models, their elements, and practical applications in speech recognition systems.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Week 2 Prof. Lin-Shan Lee TA: Chih-Chiang Chang
Outline 1. Recap 2. Acoustic Modeling 3. Homework
Feature Extraction Feature Vectors Output Sentence Input Speech Linguistic Decoding and Search Algorithm Front-endSignal Processing Language Model Construction Acoustic Model Training Language Model Text Corpora Acoustic Model Speech Corpora Lexicon
Feature Extraction - MFCC 13 dimensions vector 1st , 2nd derivatives 39 dimensions
Acoustic Modeling 03.mono.train.sh 05.tree.build.sh 06.tri.train.sh
Acoustic Modeling Feature Vectors Output Sentence Input Speech Linguistic Decoding and Search Algorithm Front-endSignal Processing Language Model Construction Acoustic Model Training Language Model Text Corpora Acoustic Model Speech Corpora Lexicon
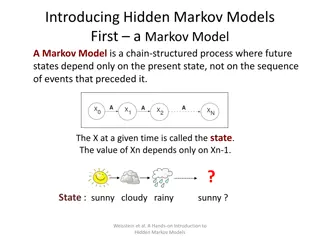
Acoustic Model Model of a phone Markov Model Gaussian Mixture Model
Hidden Markov Model (HMM) Elements of an HMM {S,A,B, } S is a set of N states A is the N x N matrix of state transition probabilities B is a set of N probability functions, each describing the observation probability with respect to a state is the vector of initial state probabilities 0.6 s1 {A:.3,B:.2,C:.5} 0.3 0.3 0.1 0.1 0.2 0.5 s2 s3 0.7 0.2 {A:.7,B:.1,C:.2} {A:.3,B:.6,C:.1}
Gaussian Mixture Model (GMM) Observation may be continuous. (e.g., mfcc) Use GMM to model continuous probability density function (for emission probabilities B).
Acoustic Model Solve three basic problems (lecture 4.0) Evaluation Problem Compute P(O| ) Forward algorithm Decoding Problem Optimal state sequence Viterbi algorithm Training Problem Adjust to maximize P(O| ) Baum-Welch algorithm
Acoustic Model Initialization Bad initialization leads to local optimal. Model Initialization: Segmental K-means Model Re-estimation: Baum-Welch
Segmental K-Means 1. Segment observations into equal length (red) 2. Estimate model parameters 3. Re-segment the observations by Viterbi (blue) 4. Re-estimate model parameters 5. Evaluate P(O| ). If not satisfied, goto 3. p1 p2 Same phoneme, 4 speakers p3 p4
Acoustic Model Triphone One acoustic model for a phoneme? The pronounce of a phoneme may be affected by its neighbors tea it two at target Triphone v.s. Monophone Consider both left and right neighboring phones (60)^3 216,000 Ex. + + and + +
Acoustic Model - Sharing Too much (216000) model to train? Share! Sharing at Model Level Sharing at State Level Shared Distribution Model (SDM) Generalized Triphone
Acoustic Model Decision Tree Decision tree decides which triphones should be combined 12 yes no sil- b+u 30 a- b+u o- b+u y- b+u Y- b+u 32 46 42 Example Questions(designed with human knowledge): 12: Is left context a vowel? 24: Is left context a back-vowel? 30: Is left context a low-vowel? 32: Is left context a rounded-vowel? U- b+u u- b+u i-b+u 24 e-b+u r-b+u 50 N- b+u M- b+u E- b+u
Acoustic Model Training Get features(previous section) Train monophone model Use previous model to build decision tree for triphone Train triphone model
Acoustic Model Training Get features(previous section) Train monophone model a. gmm-init-mono b. compile-train-graphs c. align-equal-compiled (gmm-align-compiled instead when looping) d. gmm-acc-stats-ali e. gmm-est f. numgauss = numgauss + incgauss g. Goto step c. Train several times Use previous model to build decision tree for triphone Train triphone model Initialize monophone model Get train graph model -> decode & align EM training: E step EM training: M step
Acoustic Model Training Get features(previous section) Train monophone model Use previous model to build decision tree for triphone Train triphone model a. gmm-init-model Initialize GMM ( from decision tree) b. gmm-mixup Gaussian merging (increase #gaussian) c. convert-ali Convert alignments(model <-> decisoin tree) d. compile-train-graphs Get train graph e. gmm-align-compiled model -> decode&align f. gmm-acc-stats-ali EM training: E step g. gmm-est EM training: M step h. numgauss = numgauss + incgauss i. Goto step e. Train several times
Acoustic Model Write an equally spaced alignment (for getting training started) Usage: align-equal-compiled <graphs-rspecifier> <features-rspecifier> <alignments-wspecifier> e.g. align-equal-compiled 1.fsts scp:train.scp ark:equal.ali
Acoustic Model Performing re-alignment Usage: gmm-align-compiled [options] <model-in> <graphs-rspecifier> <feature-rspecifier> <alignments-wspecifier> gmm-align-compiled $scale_opts --beam=$beam --retry- beam=$[$beam*4] <hmm-model*> ark:$dir/train.graph ark,s,cs:$feat ark:<alignment*> For first iteration(in monophone) beamwidth = 6, others = 10; Only realign at mono: $realign_iters="1 2 3 4 5 6 7 8 9 10 12 14 16 18 20 23 26 29 32 35 38 tri: $realign_iters= 10 20 30
Acoustic Model Accumulate stats for GMM training.(E step) Usage: gmm-acc-stats-ali [options] <model-in> <feature-rspecifier> <alignments-rspecifier> <stats-out> e.g. gmm-acc-stats-ali 1.mdl scp:train.scp ark:1.ali 1.acc gmm-acc-stats-ali --binary=false <hmm-model*> ark,s,cs:$feat ark,s,cs:<alignment*> <stats>
Acoustic Model Do Maximum Likelihood re-estimation of GMM-based acoustic model Usage: gmm-est [options] <model-in> <stats-in> <model-out> e.g. gmm-est 1.mdl 1.acc 2.mdl gmm-est --binary=false --write-occs=<*.occs> --mix- up=$numgauss <hmm-model-in> <stats> <hmm- model-out> --write-occs : File to write pdf occupation counts to. $numgauss increases every time.
Homework 03.mono.train.sh 05.tree.build.sh 06.tri.train.sh
TODO: Acoustic Modeling Step1. Execute the following commands. script/03.mono.train.sh | tee log/03.mono.train.log script/05.tree.build.sh | tee log/05.tree.build.log script/06.tri.train.sh | tee log/06.tri.train.log Step2. finish code in TODO script/03.mono.train.sh script/06.tri.train.sh Step3. Observe the output and results. Step4. (opt.) tune #gaussian and #iteration.
Hint (Important!) (Important!) Use the variables already defined. Use these formula: Pipe for error compute-mfcc-feats 2> $log
Hint (Important!) (Important!) Pay attention to hints colored yellow in previous section of this slide
https://drive.google.com/drive/folders/16ttKlL35nm SJj_O01TN4wfEUWKUdQagu?usp=sharing
http://speech.ee.ntu.edu.tw/courses.html Week 2 TA: r09922057@ntu.edu.tw Workstation TA: r09922057@ntu.edu.tw








")
")















")
")