Efficient Sparse Matrix-Vector Multiplication on Accelerators
Implementing an efficient SpMV kernel on fast accelerators with low arithmetic intensity can be challenging. This content discusses common and new solutions utilizing space-efficient formats like Compressed Sparse Row (CSR) and variations (CSR-DU/VI) to achieve higher operational intensity and performance. The new solution introduces BZIP2 compression, offering significant speedups in reading and decompressing matrices. Conclusions drawn provide insights into operational intensity, memory bandwidth, peak performance, and overhead comparisons for different compression techniques.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
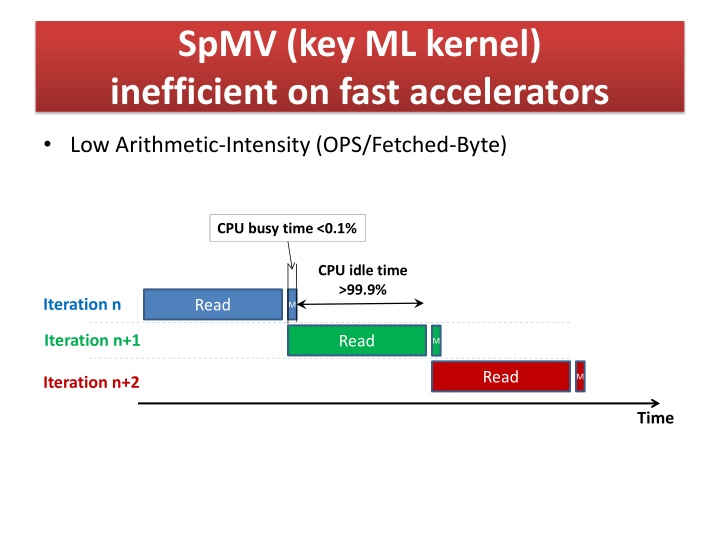
SpMV (key ML kernel) inefficient on fast accelerators Low Arithmetic-Intensity (OPS/Fetched-Byte) CPU busy time <0.1% CPU idle time >99.9% Iteration n Read M Iteration n+1 Read M Read M Iteration n+2 Time
Common Solution: Efficient Formats Space-Efficient Formats Compressed Sparse Row (CSR) Variations (CSR-DU/VI) CSR-DU CSR-VI 2.5x compression ratio Read CSR M 1.5x-4x Speedup Read CSR-DUVI M
New Solution: BZIP2 (Roman Kaplan) BZIP2-compressed matrix A bit longer to decompress A lot shorter to read Read CSR M 1.5x-4x Speedup Read CSR-DUVI M 2x-20x Speedup Read BZIP2 + CSR-DUVI M
Conclusions Compressed Input Higher Operational Intensity Main Memory BW 1048576 CPU Peak Perf. Peak Perf. With sBZIP2 + CSR-DU/+VI Overhead Ridge Point with CSR + sBZIP2 compression: 2670 Flops/Byte 65536 CSR-DUVI + sBZIP2 (8.85, 210.3) Ridge Point with DUVI + sBZIP2 compression: 2343 Flops/Byte 4096 CSR-DUVI (1.48, 69.14) External Storage BW 256 CSR-VI (0.74, 33.28) CSR-DU + sBZIP2 (8.71, 195.01) CSR-VI + sBZIP2 (3.16, 99.35) CSR + sBZIP2 (3.14, 93.01) 16 CSR-DU (0.75, 32.65) CSR (0.5, 21.21) 1 0.4 3.2 25.6 204.8 1638.4 13107.2 104857.6
")

")






















